 供需大厅
供需大厅
 登录/注册
登录/注册 供应商登录
供应商登录











荣格工业资源APP
了解工业圈,从荣格工业资源APP开始。
欢迎来到荣格工业资源网!

供需大厅

登录/注册

公众号

更多资讯,关注微信公众号

小秘书

更多资讯,关注荣格小秘书

邮箱
您可以联系我们 info@ringiertrade.com

电话
您可以拨打热线
+86-21 6289-5533 x 269
建议或意见
+86-20 2885 5256

顶部

荣格工业资源APP
了解工业圈,从荣格工业资源APP开始。



图片来源 / nextplatform
来源 / nextplatform;荣格电子芯片翻译
作者 / Timothy Prickett Morgan
在谈到AI系统时,我们不太能看到这样的情况:加速器和将它们粘合在一起形成共享计算集群的基础主板的定价列表。
但在此前于中国台湾台北举行的Computex IT会议上,英特尔(Intel)做了一件英伟达(Nvidia)和AMD都没有做过的事情:为其当前和上一代AI加速器提供了定价列表。
Gaudi 2和Gaudi 3加速器的定价信息以及这些机器的峰值吞吐量和速度的基准测试结果的公布,让我们有机会进行一些竞争分析。
英特尔谈论其定价的原因很简单。该公司正试图出售一些AI芯片来覆盖其在2025年底推出“Falcon Shores”GPU和2026年推出后续“Falcon Shores 2”GPU的成本,为此它必须证明其产品物有所值,并具有有竞争力的性能。考虑到Gaudi 3芯片于今年4月开始发货,这是英特尔于2019年12月以20亿美元收购Habana Labs后获得的Gaudi加速器系列的最后一款产品,因此这一点尤为重要。
鉴于“Ponte Vecchio”Max系列GPU的极高热能和极高制造成本,该系列GPU是阿贡国家实验室“Aurora”超级计算机的核心,已在少数其他机器上投入使用,几乎在完成这些交易后立即被搁置,英特尔正试图在被推迟的Ponte Vecchio和有望按时推出的明年年底的Falcon Shores之间架起桥梁。
正如英特尔在2023年6月透露的那样,Falcon Shores芯片将把Gaudi系列的巨量并行以太网布线和矩阵数学单元与Ponte Vecchio的Xe GPU引擎结合起来。这样一来,Falcon Shores就可以同时拥有64位浮点处理和矩阵数学处理能力。Ponte Vecchio不具备64位矩阵处理能力,只具备64位向量处理能力,这是有意为之,以满足阿贡实验室的FP64需求。这很好,但它意味着Ponte Vecchio可能并不适合AI工作负载,这会限制其吸引力。因此,Gaudi和Xe计算单元被合并为单一的Falcon Shores引擎。
我们对Falcon Shores知之甚少,但我们知道它的功率为1500瓦,比预计将于明年初开始大规模出货的顶级“Blackwell”B200 GPU高出25%,后者的功率为1200瓦,在FP4精度下可提供20拍瓦的计算能力。多消耗25%的电能,Falcon Shores在大致相同的芯片制造工艺水平下,至少在相同浮点精度下,必须拥有25%以上的性能。最好地是,英特尔最好使用其预计将于2025年投入生产的Intel 18A制造工艺来制造Falcon Shores,并且它在浮点性能上应该比这还要更强。而且,Falcon Shores 2最好采用更小的Intel 14A工艺,预计将于2026年推出。
英特尔是时候停止在晶圆厂和芯片设计业务上的胡闹了。台积电有着无情的创新节拍,英伟达的GPU路线图也是毫不松懈。“Blackwell Ultra”将在2025年带来HBM内存的提升和可能的GPU计算提升,“Rubin”GPU将在2026年推出,“Rubin Ultra”将在2027年推出。
与此同时,英特尔去年10月表示,其Gaudi加速器销售管道价值20亿美元,今年4月又表示预计2024年Gaudi加速器销售额将达5亿美元。这与AMD今年预计的40亿美元(我们认为这是保守估计,实际数字可能为50亿美元)的GPU销售额相比微不足道,也与英伟达今年在数据中心计算领域可能实现的1000亿美元以上(仅指数据中心GPU,不包括网络和DPU)的销售额相去甚远。但要实现20亿美元的销售管道,就必须为“Falcon Shores”和“Falcon Shores 2”付费,因此英特尔的动力十足。
因此,英特尔在Computex发布会上展示了Gaudi 3的定价和性能基准,以证明其与当前“Hopper”H100 GPU的竞争力。英特尔的第一个对比是针对AI训练,包括拥有1750亿参数的大型语言模型GPT-3和拥有700亿参数的Llama 2模型:

以上关于GPT-3的数据基于MLPerf基准测试的结果,而关于Llama 2的数据则基于Nvidia发布的H100芯片以及Intel的估计。GPT基准测试在拥有8192个加速器的集群上进行,其中Intel的Gaudi 3拥有128GB的HBM内存,而Nvidia的H100拥有80GB的HBM内存。Llama 2测试在仅拥有64个设备的机器上进行。
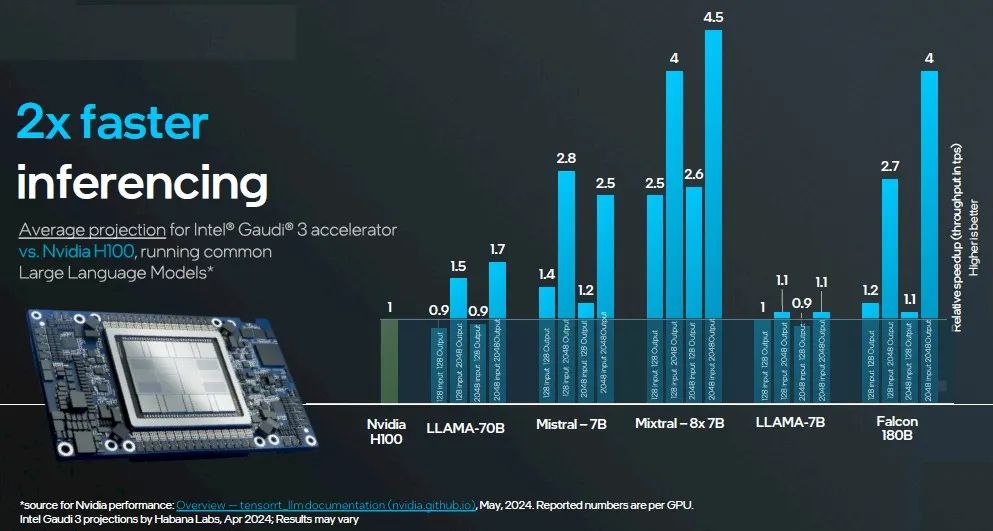
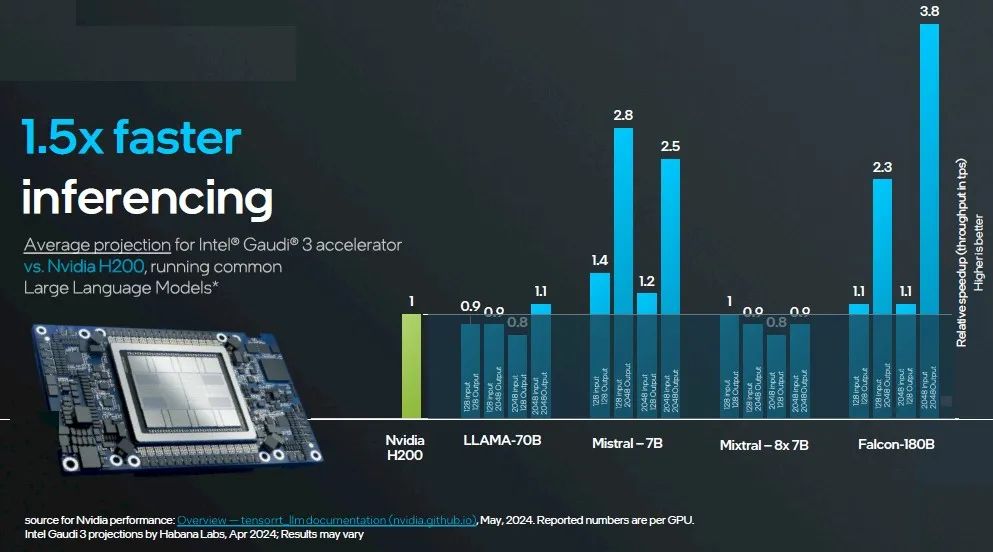
对于推理,Intel进行了两项比较:一项是将拥有128GB HBM内存的Gaudi 3与拥有80GB HBM内存的H100在一系列测试中进行比较,另一项是将拥有128GB内存的Gaudi 3与拥有141GB HBM内存的H200进行比较。Nvidia的数据在此处以各种模型为基础,这些模型在不同的模型上使用了TensorRT推理层。Intel的数据是针对Gaudi 3进行的预测。
以下是第一个比较,H100(80GB)与Gaudi 3(128GB):
这里是第二组对比,H200 141 GB与Gaudi 3 128 GB的对比:
我们要提醒大家在AI热潮中说过的两件事。第一,提供最佳性价比的AI加速器是你能够实际购买到的。第二,如果它能够以合理的精度混合进行矩阵运算,并且能够运行PyTorch框架和Llama 2或Llama 3模型,那么由于Nvidia GPU供应短缺,你可以将其出售。
但就英特尔而言,这里才是关键:

在训练方面,英特尔对Llama 2 7B、Llama 2 13B和GPT-3 175B进行了对比测试,使用的是Nvidia的真实数据,而Intel对Gaudi 3进行了估计。在推理方面,英特尔使用了Nvidia的真实数据对Llama 2 7B、Llama 2 70B和Falcon 180B进行了测试,并对Gaudi 3进行了估计。
如果你反过来计算这些性能与价格比率以及图表中提供的相对性能数据,那么英特尔假设Nvidia H100加速器的价格为23,500美元,如果我们简单地计算一下Gaudi 3 UBB的价格,那么每个的价格为15,625美元。
我们喜欢从长远来看趋势,并从更广泛的峰值理论性能角度来判断谁的性价比更高(它们是互为倒数的)。因此,以下是我们制作的表格,比较了Nvidia“Ampere”A100、H100和Blackwell B100与Intel Gaudi 2和Gaudi 3加速器,两者均采用基板配置,每块基板上有8个加速器。
请看下面的表格:
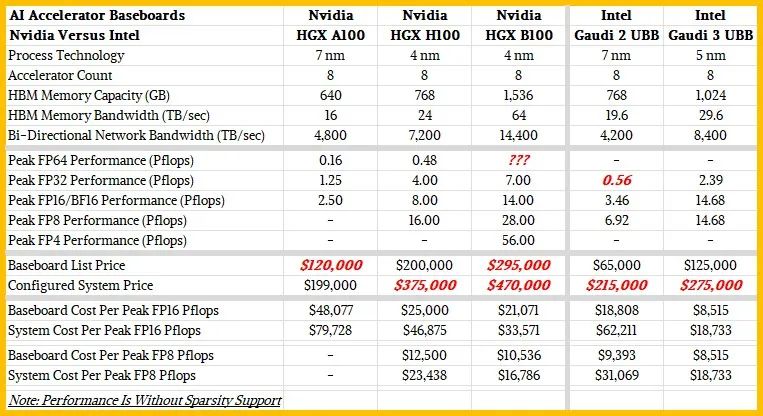
请记住,这些是针对八路主板的数字,而不是设备,它将是目前大多数AI客户计算的基本单元。
在我们最初的报道中,我们没有意识到Gaudi 3 MME矩阵引擎的BFP16吞吐量与那些矩阵单元的FP8吞吐量相同,都是1.835拍字节/秒。对此我们深表歉意。在Gaudi 2中,BF16的吞吐量是FP8的两倍,而我们错误地认为也是这个比例。此外,我们没有意识到英特尔已经发布了关于Gaudi 3规格的白皮书,而且我们使用的是不完整的简报材料。
当然,我们完全理解,对于这些设备及其主板集群来说,每个AI模型在使用计算、内存和网络适配器(在Nvidia GPU的情况下)时都有其独特的情况。工作负载和设置的不同肯定会导致性能差异。
我们也喜欢用系统的观点来思考问题,我们估算了将这些主板与一个拥有两个X86服务器插槽、2TB主内存、400 Gb/s InfiniBand网络适配器(用于Nvidia机器)、一对1.9 TB NVM-Express固态硬盘(用于操作系统)和八个3.84 TB NVM-Express固态硬盘(用于本地数据)连接到UBB所需的成本。Gaudi 2和Gaudi 3设备内置以太网端口,可以通过板载以太网端口将它们最多集群到8,192个。
我们的表格显示了这五种机器的性价比相对情况。我们使用FP16精度对所有这些设备进行评估,我们认为这是比较的良好基准,并且没有激活设备上的稀疏性支持,因为并非所有矩阵和算法都可以利用这一点。如果您想自己进行计算,也可以使用较低的精度。
根据Jensen Huang去年的一次主题演讲,HGX H100主板的价格为20万美元,因此我们实际上知道这个数字,这也与我们在市场上看到的全系统价格相一致。Intel告诉我们,带有八个Gaudi 3加速器的主板价格为12.5万美元。H100主板的峰值性能为每秒8千万亿次浮点运算,而Gaudi 3主板在无稀疏性的情况下,峰值性能为每秒14.68千万亿次浮点运算(BFP16精度)。这意味着H100系统的复杂度为每每秒千万亿次浮点运算25,000美元,而Gaudi 3为每每秒千万亿次浮点运算8,515美元,相比之下,英特尔的价格/性能比要高出2.9%。
如果你构建一个系统,并添加昂贵的CPU、内存、Nvidia机器的网络接口卡和本地存储,那么差距就会逐渐缩小。按照我们上面的配置,一个Nvidia H100系统可能需要大约375,000美元,即每每秒千万亿次浮点运算46,875美元。配置相同的Gaudi 3系统大约需要275,000美元,每每秒千万亿次浮点运算18,733美元。相比之下,Gaudi 3的价格/性能比要高出2.5倍。
从表格中可以看出,在16位浮点精度下,Gaudi 3与Nvidia Blackwell B100今年晚些时候发货时的性能不相上下。然而,在FP8下,Blackwell将占据优势,Blackwell还支持FP4,而Gaudi 3不支持。如果你加上支持、电力、环境和管理成本,这些成本是相同的,那么Nvidia和Intel之间的差距开始缩小,但显然Intel可以在某些精度上提出一些令人印象深刻的价格/性能优势。
因此,从系统级角度考虑,并对自己的模型和应用程序进行基准测试。
最后,让我们谈谈Intel的Gaudi 3收入和管道情况。如果你做数学计算,5亿美元仅相当于4万块基板,每块基板配备32,000个Gaudi 3加速器。剩余的15亿美元Gaudi管道几乎肯定是所有Gaudi 3设备的潜在销售——而不是未完成销售的积压——仅代表了销售12,000块基板(总共96,000个加速器)的机会。Nvidia今年将销售数百万台数据中心GPU,尽管其中许多不会是H100、H200、B100和B200,但其中许多将是。
原文链接:
STACKING UP INTEL GAUDI AGAINST NVIDIA GPUS FOR AI
https://www.nextplatform.com/2024/06/13/stacking-up-intel-gaudi-against-nvidia-gpus-for-ai/
*声明:本文系原作者创作。文章内容系其个人观点,我方转载仅为分享与讨论,不代表我方赞成或认同,如有异议,请联系后台。




