 供需大厅
供需大厅
 登录/注册
登录/注册 供应商登录
供应商登录











荣格工业资源APP
了解工业圈,从荣格工业资源APP开始。
欢迎来到荣格工业资源网!

供需大厅

登录/注册

公众号

更多资讯,关注微信公众号

小秘书

更多资讯,关注荣格小秘书

邮箱
您可以联系我们 info@ringiertrade.com

电话
您可以拨打热线
+86-21 6289-5533 x 269
建议或意见
+86-20 2885 5256

顶部

荣格工业资源APP
了解工业圈,从荣格工业资源APP开始。



图片来源 / nextplatform
来源 / nextplatform;荣格电子芯片翻译
作者 / Timothy Prickett Morgan
2012年,AMD正准备退出数据中心CPU业务,其数据中心GPU业务也尚未成型。在此背景下,美国能源部展现出了其经济和政治领域中一贯的明智的自利行为,并抓住机会向AMD投资,用于研究内存技术和混合CPU-GPU计算技术,以实现百亿亿次计算。虽然这笔资金并不多,但足以让AMD的工程师们在“山姆大叔”的资助下思考未来,并为AMD当前(且不可小觑)的CPU和GPU业务播下种子。
如今已经过去了十多年,“El Capitan”超级计算机即将在劳伦斯利弗莫尔国家实验室启动,成为世界上最强大的(已知)超级计算机,其强大的计算能力得益于“Antares”Instinct MI300A计算引擎所凝聚的多年艰苦的架构和封装工作。
AMD是如何走到这一步的?这在最近发表的一篇论文中得到了详细的阐述,该论文由将AMD从无名之辈带到“Antares”的关键研究人员撰写。来自AMD的技术人员加布里埃尔·洛(Gabriel Loh)在其个人档案中发布了这篇论文,该论文于今年7月初在阿根廷布宜诺斯艾利斯举行的国际计算机体系结构研讨会(ISCA)上发表。我们在上周才看到这篇论文,名为《实现AMD 千亿次异构处理器愿景》。我们发现这篇论文既有趣又有趣,考虑到这是夏天,我们认为你可能会喜欢它。
AMD去年在ISCA 2023上也发表了一篇类似的论文,名为《AMD 千亿次计算之旅的回顾》,数十名研究人员在论文中讨论了“Frontier”超级计算机的发展历程,该计算机先于并预示了MI300A和El Capitan。
本文将这两篇论文结合在一起,以飨读者。
Part 1
起初是HSA
很难想象,当美国能源部(DOE)的“设计前瞻”(DesignForward)和“快速前瞻”(FastForward)合同的资金已经到位时,AMD在数据中心领域已经跌落到何种程度,AMD肯定希望我们不要再谈论此事。我们相信救赎和同情,这也是AMD至少在GPU领域对英伟达的霸权构成一定程度的制衡,并彻底从英特尔手中夺走了CPU计算的接力棒的原因。我们也相信竞争,它有助于将游戏参与者聚集在一起,推动创新和进步。
“快速前进1”项目获得了6240万美元的资助,其后续项目“快速前进2”的资助额接近1亿美元。“设计前行”项目的第一阶段获得了2540万美元的资助,但未能找到第二阶段的相关文件。AMD通过这四项由DOE资助的投资获得了相当可观的资金,并专注于异构计算、内存处理和缓存内存,以及低电压逻辑和新型内存接口,这些技术在“快速前进1”中得到应用,而在“快速前进2”中则侧重于低电压逻辑和新型内存接口。
“设计前行”项目也有两个阶段,参与者专注于为百亿亿次系统开发互联和协议,然后是系统设计和集成(有关这些努力的概述请参见此处。)2015年,有一项名为PathForward的类似项目,投入了更多的资金,开始开发超算级别的系统,而不是进行研究。该项目在英特尔、英伟达、Cray、IBM、AMD和惠普企业之间进行了投资,总额达2.58亿美元,这些厂商也提供了相等的资金,使总投入达到4.5亿美元。
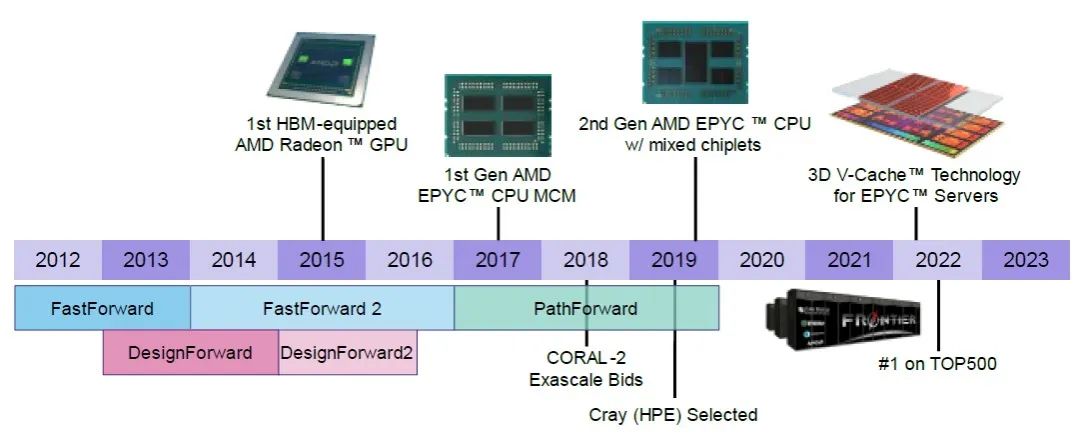
总的来说,八年间至少投入了6.378亿美元来开发超算硬件设计。在很大程度上,AMD加上Cray加上HPE的团队在美国资助的超算设备方面至少赢得了胜利。虽然欧洲也安装了一些使用相同架构的大型设备,但EuroHPC合资企业正在通过自研的CPU、加速器和互联技术来分散风险。
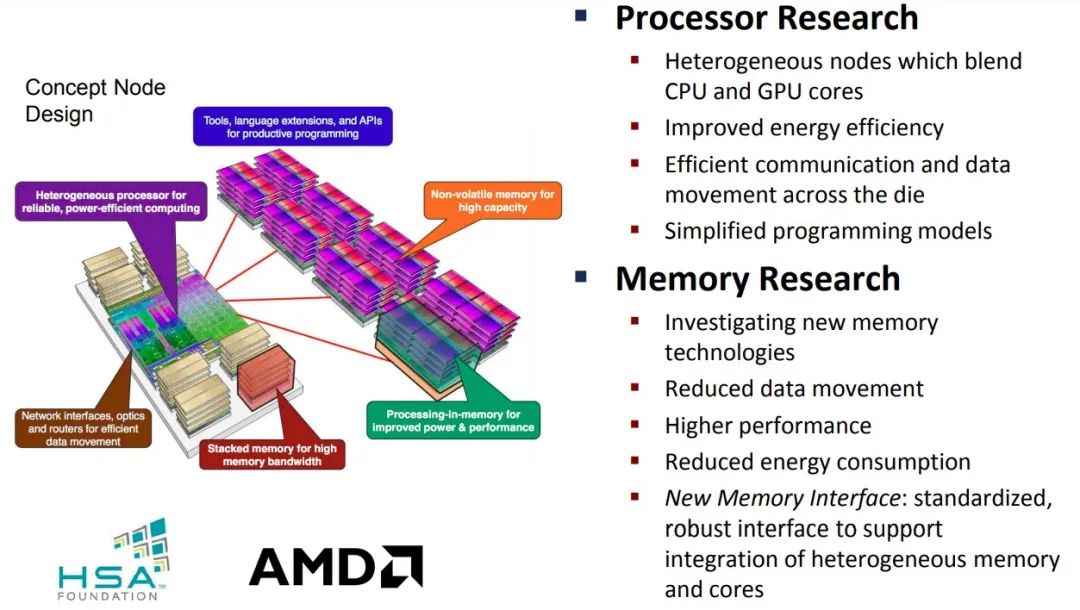
每个项目都是从想法和漂亮的图纸开始的,AMD在十多年前开始憧憬的未来也始于这一想法,现在这一想法已经写在了这13名AMD技术人员的论文中,其中许多人因为在AMD所谓的加速处理器单元上的工作而在HPC和AI领域成为了知名人士。早在开始时就采用了所谓的异构系统架构。这张图是2012年的,来自FastForward 1项目:
以下是AMD当时所称的Exascale异构处理器的第一代示例:
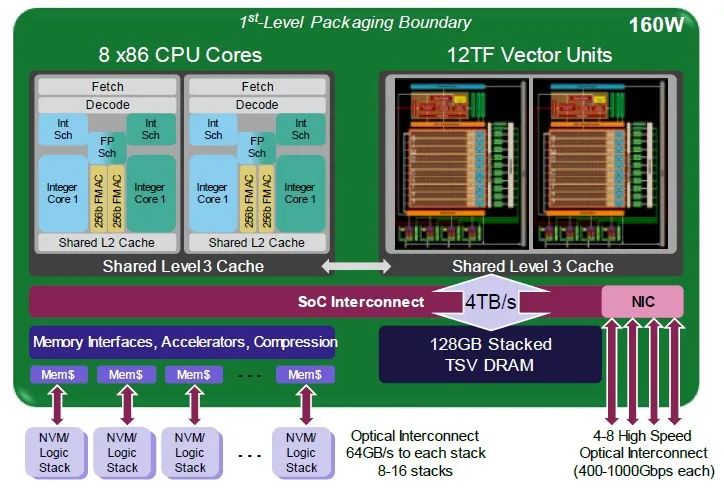
这款EHP-1的设计实际上是四核心设计,每核心配有两组256位向量,与一个配有两组流式多处理器的GPU复杂体相连,每组流式多处理器具有每秒6万亿次64位向量运算的运算能力。显然,这种芯片设计还支持FP32格式,但可能不支持更低精度的格式。请记住,这款芯片专注于HPC工作负载,而我们现在所知的基于变换器的AI工作负载尚未出现。
AI工作负载具有统计学性质,可以在牺牲一些精度的情况下提高吞吐量,并最终得出正确的答案。HPC工作负载更具有确定性(至少在64位数据和良好的算法的范围内),精度越高,得到的答案越好。我们生活在一个试图在新的HPC应用程序中使用更低精度的时代,尽管这听起来像是异端邪说,但它可能还会发挥作用。
到2014年,AMD已经意识到,从14/16纳米到5纳米这一代芯片的单位面积正常化成本将增加2.5倍,于是它从单片式处理器和GPU复杂体切换到了chiplet设计。

在这个阶段,AMD也开始质疑美国能源部资助其研究的处理器在内存(PIM)方法的经济和技术可行性,以及在计算引擎中使用NVRAM的问题。AMD还直言不讳地承认对能够将多少DRAM芯片堆叠到HBM内存银行上的乐观程度。上图显示了16个晶圆堆叠在一起的情况,直到明年,当12个晶圆堆叠成为商业上可行的情况下,我们一直停留在8个晶圆堆叠的状态。
你还会注意到EHP v2将DRAM内存堆叠在GPU芯片块上方,这确实是一个雄心勃勃的设计。
2016年,AMD回到了设计板上,对EHP设计进行了第三代改进:
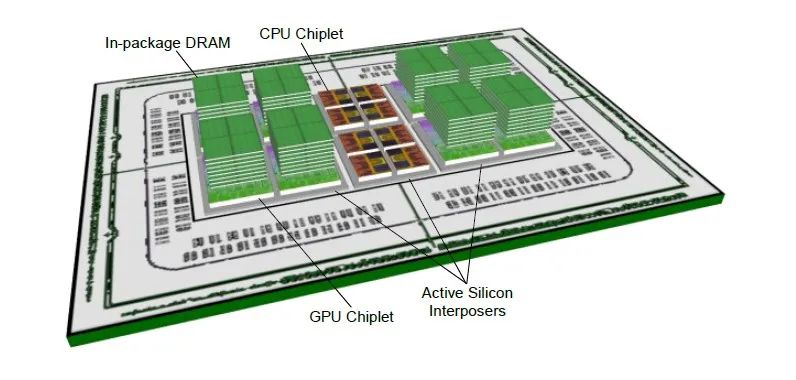
现在,GPU芯片块被切成两半,在GPU上方有八个高HBM堆栈,而CPU芯片块位于计算引擎的中心,并可能访问该HBM内存。EHP v3设计在GPU下方使用了一个有源中介层,这意味着它们有像路由器或放大器之类的有源组件,而不是被动中介层中唯一的金属导线。
AMD最终发现,将内存堆叠在计算层之上,再将计算层堆叠在主动中间层之上的主动中间层设计并不具有经济可行性。这导致了2018年的EHP v4设计:
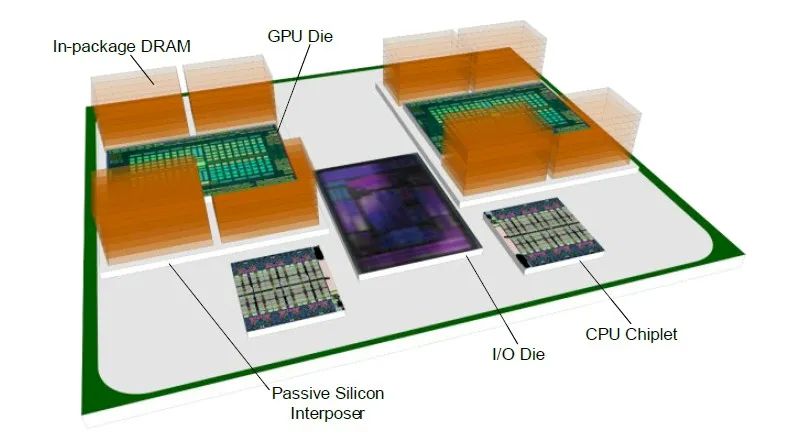
在EHP设计的前三个迭代中,AMD试图将所有组件都塞进Epyc SP3服务器插槽中。通过PathForward项目,AMD不再以插槽为单位进行思考,而是从系统主板级出发,并利用Infinity Fabric链接在主板上拼接出一个更大的“插槽”。AMD拥有自己的GPU插槽包装设计,并密切关注微软和Meta Platforms创建的OCP加速模块(OAM)插槽,该插槽于2019年被采用为OCP标准((AMD显然很早就知道了,直到今天,它的Instinct GPU都采用了这个插槽。)。
AMD为Frontier超级计算机设计的实际计算引擎复杂结构中,CPU计算与GPU计算的比例为1:4,这一事实已被广泛报道并讨论。但正如这两份AMD的论文以及我们带您了解的其他示意图所展示的那样,这确实是一个八核心chiplet块与一个GPU chiplet块的1:1配对,每个节点有八个这样的配对。请看:
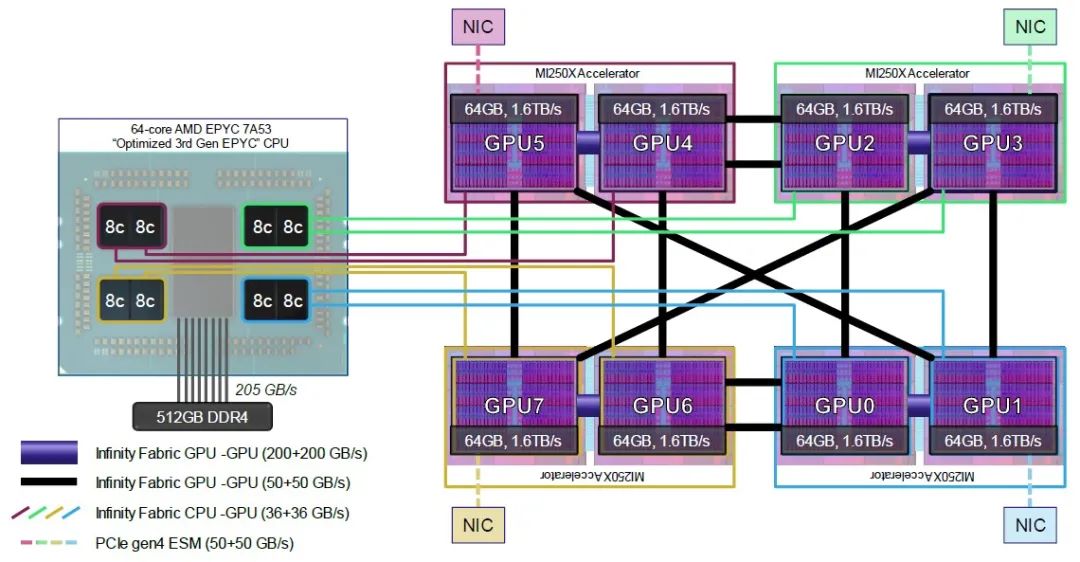
Frontier节点在某种程度上可以说是一个虚拟APU,并且被编程为这样的功能。GPU之间有更粗的Infinity Fabric管道,以便它们可以快速、高效地共享数据,GPU chiplet对对之间的耦合非常紧密,相邻的GPU复杂体之间通过略微更细、但同样快速的Infinity Fabric管道连接,而CPU到GPU的链接则比这些管道还要更细一些。
虽然接近,但还是差了一点,但美国需要一个百亿亿次系统,你必须做你必须做的事情。
随着去年12月宣布的El Capitan的Instinct MI300A,AMD已经做了它一直想做的事情:创建一个真正的APU。该公司还创造了有史以来最复杂的计算引擎插槽。以下是其性能和速度:

以下是该复杂结构的横截面:
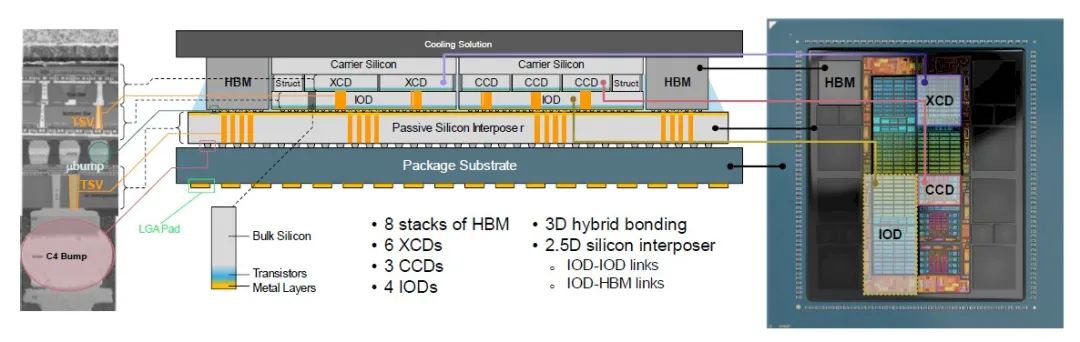
这是一个相当复杂的硅和金属夹层,不是吗?
虽然我们赞赏所有硬件进步,但归根结底是这样的:因为CPU和GPU真正地实现了统一,所以代码与仅使用CPU架构的情况没有太大区别。第二篇关于MI300A的论文给出了一个示例,展示了不同场景下的数据移动和同步。请看:
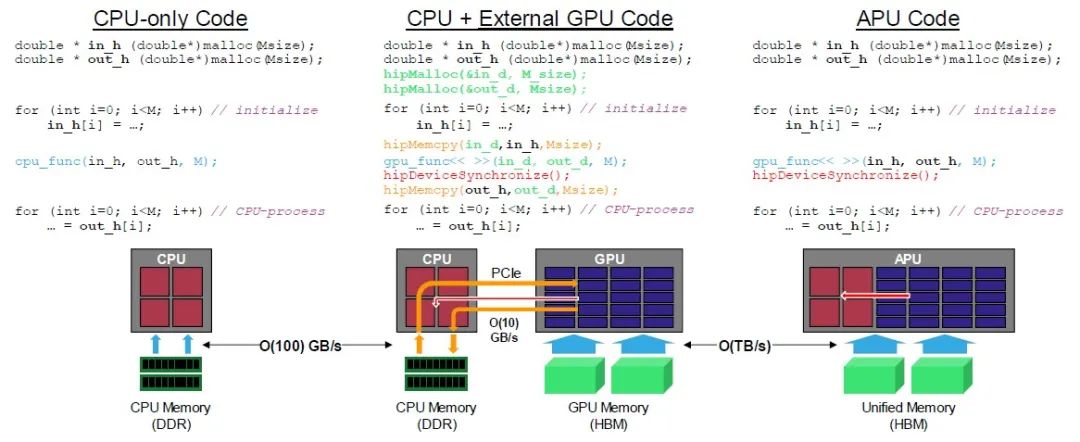
MI300A架构旨在将CPU和GPU紧密耦合在一起,并使用Epyc CPU CCD上的PCI-Express端口与外界连接,如下所示:
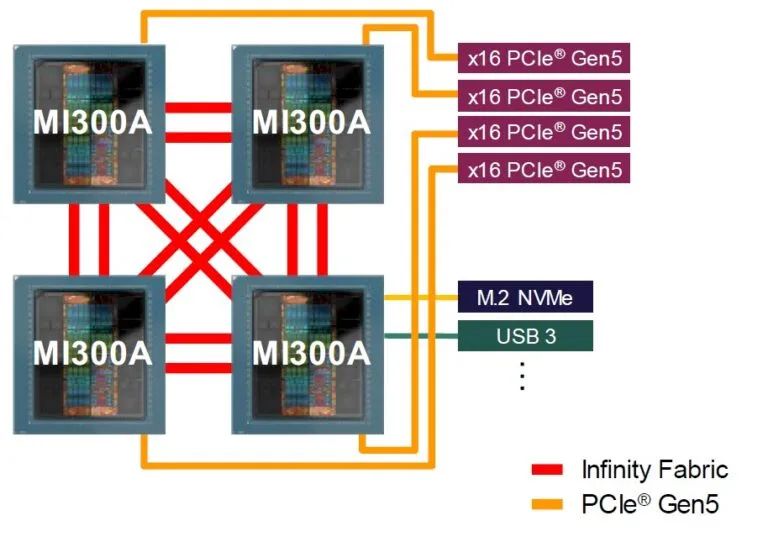
我们想知道的是,企业是否会购买MI300A服务器,或者使用Antares家族中的Epyc CPU与MI300X GPU的分离式组合。这将取决于价格、可用性和企业所需的CPU-GPU计算比率。我们想知道的是,在价格、价格/性能和热性能方面,MI300A与Nvidia的Grace-Hopper或Grace-Blackwell分离式CPU和GPU组合相比如何。
到目前为止,我们还没有足够的数据来进行这样的比较。但我们会继续关注。
原文链接:
https://www.nextplatform.com/2024/07/17/amds-long-and-winding-road-to-the-hybrid-cpu-gpu-instinct-mi300a/
*声明:本文系原作者创作。文章内容系其个人观点,我方转载仅为分享与讨论,不代表我方赞成或认同,如有异议,请联系后台。




