 供需大厅
供需大厅
 登录/注册
登录/注册 供应商登录
供应商登录











荣格工业资源APP
了解工业圈,从荣格工业资源APP开始。
欢迎来到荣格工业资源网!

供需大厅

登录/注册

公众号

更多资讯,关注微信公众号

小秘书

更多资讯,关注荣格小秘书

邮箱
您可以联系我们 info@ringiertrade.com

电话
您可以拨打热线
+86-21 6289-5533 x 269
建议或意见
+86-20 2885 5256

顶部

荣格工业资源APP
了解工业圈,从荣格工业资源APP开始。



图片来源 / nextplatform
来源 / nextplatform;荣格电子芯片翻译
作者 / Timothy Prickett Morgan
训练AI模型的成本很高,只要可以将这些日益复杂的变换器模型的推理成本降低到一定程度,世界就可以容忍这种高成本。训练是研究、开发和运营成本,而推理则是关于赚钱——无论是通过发现新的收入来源,还是通过从构成企业或其他机构的工作流程中消除昂贵的人力。
鉴于此,近年来人们对推理硬件及其成本的关注度更高,尤其是因为变换器模型需要大量的节点来提供低响应时间——大约200毫秒,这是人类和蚊子的平均注意力持续时间。
Artificial Analysis是一家对AI模型性能和定价进行了有趣独立分析的公司,在Xitter上发表了一篇有趣的文章,其论点是AMD去年12月宣布并现已发货的“Antares”Instinct MI300X GPU加速器,当谈到运行Meta Platforms刚刚发布的Llama 3.1 405B模型时,与Nvidia相比,我们将处于非常有利的地位。
众所周知,我们认为鉴于PyTorch框架和Llama模型的开源性质,它们都来自Meta Platforms,并且与Open AI框架和由其他超大规模公司和云服务提供商创建和使用的封闭源AI模型具有竞争力,因此我们认为PyTorch/Llama组合将非常受欢迎。并非巧合的是,AMD的技术人员确保Antares GPU首先针对该堆栈进行了优化。
以下是基本的前提:要容纳Llama 3.1的405亿参数变体的权重和包括权重和内存开销在内的所有数据,需要多少个GPU?看看下面的图表:
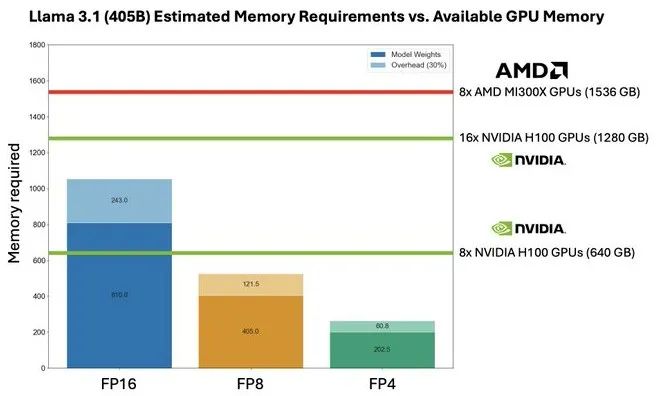
该比较仅比较AMD MI300X与Nvidia原始的“Hopper”H100,并将2023年11月宣布的“Hopper”H200 GPU作为未来的产品进行参考,因此它与Nvidia今年3月宣布的尚未在B100和B200形式因子上大量出货的“Blackwell”GPU一样未被包含在图表中。因为这些数字很难读懂,根据Artificial Analysis的数据,要加载Llama 3.1 405B模型的权重需要810 GB的存储空间,而要在Llama 3.1模型的原生FP16处理中保留30%的余量则需要另外243 GB的存储空间。这总共需要1053 GB的存储容量。
如果你在数学运算中(比喻性地眯起眼睛以模糊数据)将精度降低到FP8,那么数据将缩小一半,只需要405 GB的权重和121.5 GB的余量。这意味着你可以将其放入一半的计算引擎中。如果你将精度降低到FP4,进一步眯起眼睛,则可以将HBM内存的数量和所需的GPU数量减半,因为数据缩小了一半。再次强调,为了减少数据精度,LLM的响应精度也会有所降低。
使用市面上常见的Hopper H100 GPU以及其仅有的80 GB HBM内存,您需要两张八路HGX卡来容纳Llama 3.1 405B的权重和余量(实际上,您需要13.2个GPU,但在实践中,您必须以8个为单位购买它们)。如果你将精度降低到FP8,你可以在一个服务器系统上使用一块带有八个Hopper GPU的HGX主板来容纳整个模型。
使用一块AMD MI300X八路GPU主板的系统可以轻松容纳Llama 3.1 405B模型的模型权重。实际上,如果你能以这种方式购买的话,只需要5.5块GPU即可。从另一个角度来看,只要有合适的MI300X GPU,就可以在八路系统板的共享内存中运行未来Llama模型的推理(假设权重和开销按线性比例增长),该模型具有约590亿个参数。
我们不喜欢H200、B100和B200 GPU不在比较列表中,我们也一直认为,除了性能和内存容量外,资金也是必须考虑的因素。因此,我们借鉴了Artificial Analysis的想法,并在下表中进行了应用:
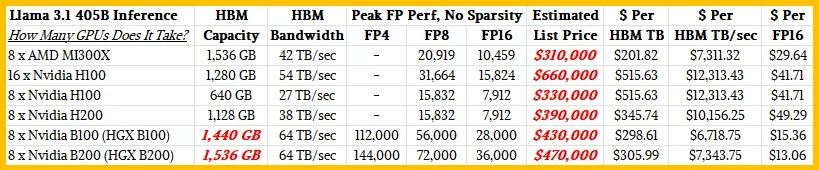
在查看该表格之前,我们需要指出Nvidia B100和B200规格中的一些奇怪之处。Nvidia Architecture Technical Brief显示,HGX B100和HGX B200系统板将具有高达1.536TB的内存,这意味着每个B100 GPU有192GB内存。但是DGX B200的技术规格表显示它只有1,440 GB的HBM内存,这比B100 GPU的180 GB少了很多(我们未能找到B100服务器的技术规格表)。我们认为B100和B200将拥有不同的内存容量,就像Hopper一代的H100和H200一样,我们不相信B200的内存容量会比B100低。
因此,目前我们预测,HGX B100系统板上的B100将拥有180 GB的内存,而HGX B200系统板上的B200将拥有192 GB的内存。我们已经根据这一预测为我们的假设GPU系统配置了内存。
说到这里,考虑到当前GPU的价格,我们认为装有GPU的机器将用于LLM推理和LLM训练。因此,我们使用这些八路GPU主板构建的服务器的基本配置相当强大,具有双X86处理器(许多核心)、大量主内存(2 TB)、大量用于东西向流量的网络带宽(八张200 Gb/sec卡)以及大量本地闪存存储(6.9 TB)。我们认为,这样配置的服务器(不包括GPU)的成本约为15万美元。
对于 GPU 定价,我们使用了以下内容:
AMD MI300X 192 GB:20,000 美元
英伟达 H100 80 GB:22,500 美元
英伟达 H200 141 GB:30,000 美元
英伟达 H100 180 GB:35,000 美元
英伟达 H200 192 GB:40,000 美元
最终的系统价格是将GPU板卡添加到基础X86硬件后得出的,旨在说明情况,而非购物指南。实际价格会受到需求压力和时间因素的影响,人们通常会为GPU支付更多费用。对于推理任务,主机服务器上的网络连接和内存、闪存可能可以减少很多。但在紧急情况下,当试图在该系统上进行训练时,轻量配置会受到限制。
因此,以下是我们的看法。是的,HBM内存容量将决定推理服务器的配置,而您希望在保持一定的模型增长空间的前提下,以尽可能低的价格购买尽可能少的GPU。
因此,您需要考虑HBM内存的单位成本,正如您所看到的,在系统层面上,如果我们对AMD和Nvidia GPU的基本定价大致正确,那么AMD在MI300X上将具有显著优势。
一些AI工作负载对内存带宽的敏感度要高于对内存容量或在特定精度下的计算能力的敏感度。在这方面,我们预计基于MI300X的系统在每单位内存带宽的成本方面将与使用Nvidia B200 GPU加速器的系统持平。基于Nvidia HGX B200板的系统在1.5TB内存相同的情况下,将提供51%更多的带宽,但成本却高出51%。(我们分别得出了这两个数字。我们没有猜测价格涨幅会与内存带宽涨幅相匹配。我们将看看Nvidia和市场实际上会怎么做。)
如果B100的价格按我们预期的那样,使用B100的系统在内存容量和内存带宽方面的性价比将更好,但B100预计不会提供相匹配的计算性能。Nvidia没有解释B100和B200的FP4性能差异是真实的,但B200的性能预计将高出28.6%。B200可能比B100多出6.7%的内存容量将有所帮助,但看起来,B100在开始发货后的内存带宽将低于B200,并且将激活的流式多处理器数量也将少于B200。
有趣的是,就原始峰值浮点性能规格而言,Nvidia B100将轻松超越AMD MI300X,而B200的表现则会更出色。正如您所见。在峰值FP16性能水平上,将B100/B200与MI300X进行比较时,Nvidia的优势大约是两倍。
然而,AMD MI300X现已开始发货,其性能与Nvidia H100和H200相当,在每美元的性能方面要高出41%至66%。但请注意:根据Nvidia在H200发布期间发布的基准测试数据,在真实的Llama 2 70B推理测试中,H200的性能比H100高出1.9倍。因此,请根据您购买GPU的目的,谨慎考虑浮点运算量与内存容量、浮点运算量与内存带宽的比例。
在上述两个比例上,AMD MI300X与Nvidia H100和H200大致处于同一水平,但Nvidia B100和B200的每内存容量的浮点运算量和每内存带宽的浮点运算量要多得多,由于内存限制,在实际工作负载中,这些性能可能无法实现。
因此,在购买之前,请务必进行测试、测试、再测试。今年晚些时候将推出的AMD MI3 25X拥有288 GB和6 TB/s的内存带宽,明年推出的MI350拥有288 GB和未知的内存带宽,2026年推出的MI400X同样如此。
原文链接:
https://www.nextplatform.com/2024/07/29/stacking-up-amd-versus-nvidia-for-llama-3-1-gpu-inference/
*声明:本文系原作者创作。文章内容系其个人观点,我方转载仅为分享与讨论,不代表我方赞成或认同,如有异议,请联系后台。




