 供需大厅
供需大厅
 登录/注册
登录/注册 供应商登录
供应商登录











荣格工业资源APP
了解工业圈,从荣格工业资源APP开始。
欢迎来到荣格工业资源网!

供需大厅

登录/注册

公众号

更多资讯,关注微信公众号

小秘书

更多资讯,关注荣格小秘书

邮箱
您可以联系我们 info@ringiertrade.com

电话
您可以拨打热线
+86-21 6289-5533 x 269
建议或意见
+86-20 2885 5256

顶部

荣格工业资源APP
了解工业圈,从荣格工业资源APP开始。


据传闻,预计 Nvidia 在 2027 年推出“Rubin Ultra”GPU 计算引擎之前不会为其 GPU 内存捆绑 NVLink 协议提供光互连。这意味着,每个设计加速器的人——尤其是由超大规模和云构建商内部设计的加速器——都希望通过在 Big Green 之前部署光互连来获得优势,从而在 AI 计算方面超越 Nvidia。
鉴于加速器到加速器和加速器到内存需求的巨大带宽瓶颈,对光互连的需求如此之高,因此筹集风险投资不是问题。
先谈谈 Xscape Photonics
我们看到这方面的行动越来越多,今天我们要谈谈 Xscape Photonics,这是一家从哥伦比亚大学研究中分离出来的光互连初创公司。
无论您是否知道,哥伦比亚大学都是互连和光子学的温床。
Al Gara 和 Norman Christ 教授构建了一台由 DSP 驱动的超级计算机,该计算机具有专有互连功能,用于运行量子色动力学应用,该计算机于 1998 年获得 Gorden Bell 奖。这项 QCDSP 系统研究为 IBM 的 BlueGene 大规模并行超级计算机奠定了基础,Gara 是该计算机的首席架构师。(Gara 搬到了 Intel,也是其假定的继任者——阿贡国家实验室的“Aurora”超级计算机的架构师。)
哥伦比亚大学的一组完全不同的研究人员致力于硅光子学,他们中的许多人已经联手创建了 Xscape Photonics。该大学光波研究实验室的负责人 Keren Bergman 是该公司的联合创始人之一,他一直在使用光子学来降低在系统中移动数据的能量。联合创始人 Alex Gaeta 是这家初创公司的总裁,最初是其首席执行官,他在量子和非线性光子学方面做了基础工作,即参数放大器和光频梳发生器。联合创始人 Michal Lipson 发明了一些关键的光子学组件,例如微环调制器和纳米锥度耦合器。联合创始人 Yoshi Okawachi 是一种称为光频梳的特殊激光器的专家。
当这些哥伦比亚大学的研究人员决定将他们的光互连理念商业化时,有趣的是,在 Gaeta 决定减少他的职责以重返大学教授职位后,他们选择了 Xscape 的首席执行官 Vivek Raghunathan,他是联合创始人之一,而不是来自哥伦比亚大学。
而Nvidia 的投资很有趣,因为需要将更多的 GPU 相互连接起来,而不是这家 GPU 巨头在 3 月份宣布的 GB200 NVL72 机架级系统中使用“Blackwell”B100 GPU 加速器使用铜基 NVLink-NVSwitch 互连。通过在 GPU 及其内存之间连接光管,Nvidia 可以将数据中心变成一个巨大的虚拟 GPU。你可以打赌,这正是 Nvidia 想要做的,并且早在 2022 年就通过其带有 CPO 概念设计的 NVSwitch 暗示了这一点。
AI 加速器的问题在于,无论其架构如何,一旦你走出给定设备的边缘,计算元件或内存之间的带宽就会开始逐渐减少,而且速度相当快。
对于任何加速器,都需要使用电信号将 HBM 堆叠内存放在非常靠近计算引擎的位置,这意味着您只能在该芯片周围的给定圆周内封装这么多内存。(您只能将内存堆叠得如此之高以增加容量,即使这样做,也不会增加带宽。只有更快的内存和更多的内存端口才能增加带宽。由于 HBM 价格昂贵且供不应求,我们看到 GPU 加速器路线图做了一些奇怪的事情,以匹配他们有时拥有的超能力 GPU 所能获得的有限内存容量和带宽。
Raghunathan 说,归根结底,是从加速器传出的数据的“逃逸速度”,这就是 Xscape Photonics 这个名字的由来。

再看平均CPU利用率
这些是我们经常谈论的数字,但很高兴将它们都放在一个地方以显示逐渐减少,当您查看一组 Nvidia GB200 混合动力车时,它的规模约为 160 倍,每个“Grace”CG100 Arm 服务器 CPU 有两个“Blackwell”GB100 GPU 加速器。这种带宽逐渐减少是针对 400 Gb/秒的 Quantum 2 InfiniBand 端口测量其中一个 GPU 的过程,该端口通常用于让 GPU 与集群中和其自身节点之外的其他 GPU 通信。
那么,这种带宽缩减意味着数据无法足够快地进出 GPU 会产生什么影响呢?在非常昂贵的设备上利用率低。
对于 AI 训练和推理,Raghunathan 引用了 Alexis Bjorlin 的数据,他曾经为 Meta Platforms 运行基础设施,但现在已经转任 Nvidia DGX Cloud 的总经理。看一看:

“因此,对于训练,随着你继续扩展,大多数 GPU 的问题已经从 GPU 设备级性能转移到系统级网络问题,”Raghunathan 告诉 The Next Platform。“根据工作负载的不同,您最终会花费大量时间在 GPU 之间进行通信。在 Meta 显示的图表中,他们谈到了某些工作负载,其中近 60% 的时间都花在了网络上。同样,当您考虑推理时,您正在查看最先进的 GPU,它们在进行 ChatGPT 搜索时具有 30% 到 40% 的利用率。这种低 GPU 利用率是我们的客户在继续购买数十亿美元 GPU 时想要解决的根本问题。
这个数学很简单。在 50% 的利用率下,峰值计算的一定百分比是由进出 GPU 的有限带宽预先确定和禁止的,这意味着 GPU 的成本是您想象的两倍,这意味着您浪费了一半的钱。
现在,公平地说,我们非常怀疑全世界的平均 CPU 利用率是否高于 50%。但平均 CPU 的成本也不为 30,000 美元。每年大约 1500 万台服务器的平均成本可能接近 1,000 美元。但这仍然是每年数百亿美元进入低效率的烟囱。GPU 的浪费是“损失”的钱超过一个数量级,这就是每个人都吓坏了的原因。
“正是这种带宽的缩减是我们真正想在 Xscape Photonics 解决的问题,”Raghunathan 说,这与我们从 Ayar Labs、Lightmatter、Eliyan、Celestial AI、Ultra Accelerator Link 联盟成员等那里听到的许多评论相呼应。“我们该如何解决这个问题呢?我们认为,将所有从 GPU 逸出的电信号直接转换为同一封装中的光信号,并在我们将 GPU 和内存池连接在一起时最大限度地利用这一点,是扩展 GPU 性能的最经济高效和节能的方法。
最后Xscape 团队解决方案
Xscape 团队想出的诀窍是一种激光器,它可以同时从光纤中驱动多个波长——例如多达 128 种不同的颜色,这可能代表着比驱动四种不同颜色的光互连中使用的激光器高 32 倍的带宽。此外,Raghunathan 说,Xscape 方法及其 ChromX 平台将使用更简单的调制方案,如 NRZ,这些方案不会像 PAM-4 等高阶调制方案那样影响延迟,并且近年来已被用于提高 InfiniBand 和以太网的带宽。
也许同样重要的是,ChromX 光子学平台是可编程的,因此提供的波长数量与特定 AI 训练或推理工作负载的需求以及加速器与其 HBM 内存之间的连接需求相匹配,所有这些都在交换结构基础设施中进行。可编程激光器首先出现,概念如下:
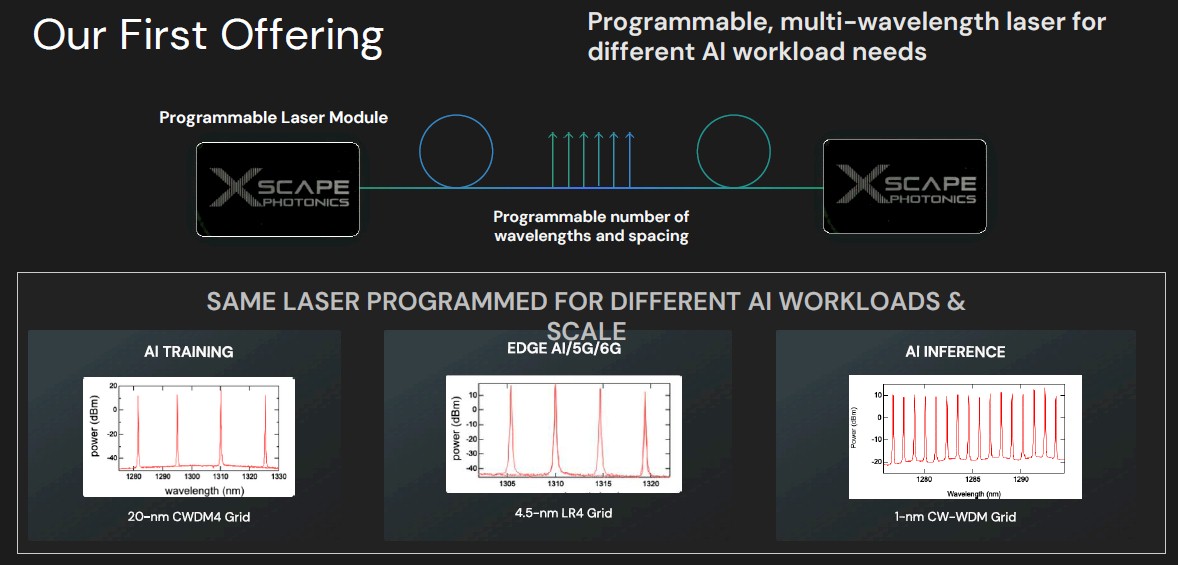
此图表在左侧显示了用于 CWDM4 收发器的激光器所需的四个波长,以便为 AI 训练集群创建互连。
中间是制作 LR4 光收发器所需的四种不同波长,当您必须使用光链路跨越两个数据中心并同步链接它们时,通常会使用这种波长,以便可以在两个数据中心上进行培训,就好像它们是一个更大的数据中心一样。
右侧是一个推理引擎,它有一个开关加速器和 HBM 内存复合体,这与 Nvidia 对 NVLink 和 NVSwitch 所做的有很大不同,有 16 种不同的波长。
不同的波长对应于设备之间的预期距离。根据 Raghunathan 的说法,设备之间的训练距离通常为 2 公里或更短,跨数据中心边缘用例预计在 20 公里到 40 公里之间,但有些人说的是 10 公里到 20 公里。推理具有更多的波长,设备之间的距离预计在 10 米到 200 米之间,并且需要更多的带宽才能使这些设备高效运行。
后一点与计算和内存的分解结构架构有关,我们认为它对训练和推理都有效,这很有趣。那么让我们看看这一点:
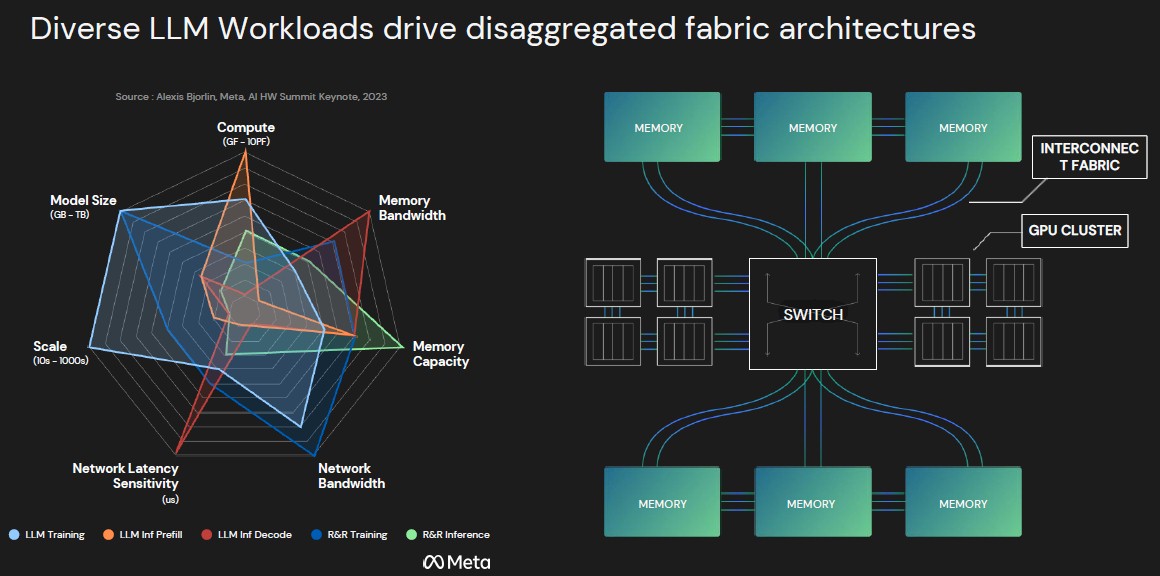
在这种架构中, HBM 内存没有连接到 GPU,而是在内存中粘合在一起,这些内存可能会在机架中物理不同的机架上或整个机架上实现。GPU(或者说任何类型的 AI 或 HPC 加速器)都存储在一起,因此它们可以在一致性域中共享缓存中的本地数据,但所有这些数据都通过一个交换机链接,该交换机将加速器池与内存池交叉连接。上述每个管道都是一个光链路,其属性可以通过 ChromX 平台进行编程,在正确的频率上具有正确数量的波长,以满足带宽和距离(以及延迟)要求。
“我们的技术几乎消除了成本障碍和规模障碍,并使其非常可靠,因为我们只需要一个激光器就可以泵浦一块硅片,而且我们可以从单个设备产生多达数百个波长,”Raghunathan 说。“我们提供了一个全新的带宽扩展向量。核心 IP 由哥伦比亚大学独家授权,完全归我们所有。其愿景是将封装内通信带宽与封装外通信逃逸带宽相匹配。我们认为,当我们使用我们的多色方法时,我们可以与之匹配,以便大型数据中心或多个数据中心像一个大型 GPU 一样运行。
目前,Xscape Photonics 并没有试图制造支持这种分解式光子学结构的网络接口或交换机,而是试图创造合适的低功率、多色激光器,其他人会想要购买来制造这些设备。他们有一个激光器处理所有这些频率,而其他激光器必须使用多个激光器来完成这个任务。这个想法是将加速器及其存储器的互连的总功耗降低 10 倍,并将带宽提高 10 倍,从而将每个带宽的能耗降低 100 倍。
参考来源:https://www.nextplatform.com/2024/10/17/one-laser-to-pump-up-ai-interconnect-bandwidth-by-10x/


